
现在让我们设好番茄钟放一首好听的音乐开始学习吧 🌈 😋
1. 为什么要使用 goroutine
在实际开发里,你经常会遇到这类需求:
- 同时处理很多 IO(HTTP 请求、数据库、文件、消息队列)。
- 把一个大任务拆成多个子任务并发执行(批处理、爬虫、转码)。
- 后端服务需要同时处理大量连接与请求。
传统做法通常是“一个任务一个线程”。但 OS 线程创建、切换的成本较高,线程数也不可能无限增长。
goroutine 的意义:用更轻量的并发执行单元,把并发写成“语言层面的常规代码”,并交给 Go runtime 调度。
2. 进程、线程、并发与并行(先把概念对齐)
- 进程(Process):程序在操作系统中的一次执行过程,是资源分配与调度的基本单位。每个进程有独立的地址空间。
- 线程(Thread):进程内的执行单元,是程序执行的最小单位。一个进程可以包含多个线程。
- 并发(Concurrency):多个任务在同一段时间内交替推进,强调“组织与调度”。单核 CPU 上多任务通常体现为并发。
- 并行(Parallelism):多个任务在同一时刻真正同时执行,强调“硬件多核 + 调度”。多核 CPU 上更容易实现并行。
用一句话理解:
- 并发:你同时“做很多事”。
- 并行:你同时“真的在做很多事”。
说明图(可视化对比):
flowchart LR
A[任务A] --> Q[并发:轮流推进]
B[任务B] --> Q
Q --> S[完成]
A2[任务A] --> P1[并行:CPU 核 1]
B2[任务B] --> P2[并行:CPU 核 2]
P1 --> S2[完成]
P2 --> S2
3. Go 语言中的“协程”:goroutine 与主线程
在 Go 里,我们通常把 goroutine 称为“协程”。更精确地说:
- goroutine 是 Go runtime 管理的用户态并发执行单元。
- 使用方式非常直接:在函数调用前加
go关键字,就启动一个 goroutine。
go fn() // 启动一个 goroutine 并发执行 fn
- OS 线程通常有固定栈(常见约 2MB)。
- goroutine 初始栈很小(常见约 2KB),并且可按需增长。
- goroutine 的创建、切换开销通常比线程更低,因此可以支撑“很多并发任务”。
你可以把 goroutine 理解为:
- “像线程一样写并发”,
- 但成本更低,
- 调度由 runtime 负责。
4. goroutine 的基本使用:从一个例子开始
下面代码看似启动了 goroutine,但如果 main 结束,程序就直接退出,未必等 goroutine 跑完。
package main
import (
"fmt"
"strconv"
"time"
)
func test() {
for i := 1; i <= 10; i++ {
fmt.Println("test() hello", strconv.Itoa(i))
time.Sleep(50 * time.Millisecond)
}
}
func main() {
go test()
for i := 1; i <= 10; i++ {
fmt.Println("main() hello", strconv.Itoa(i))
time.Sleep(50 * time.Millisecond)
}
}
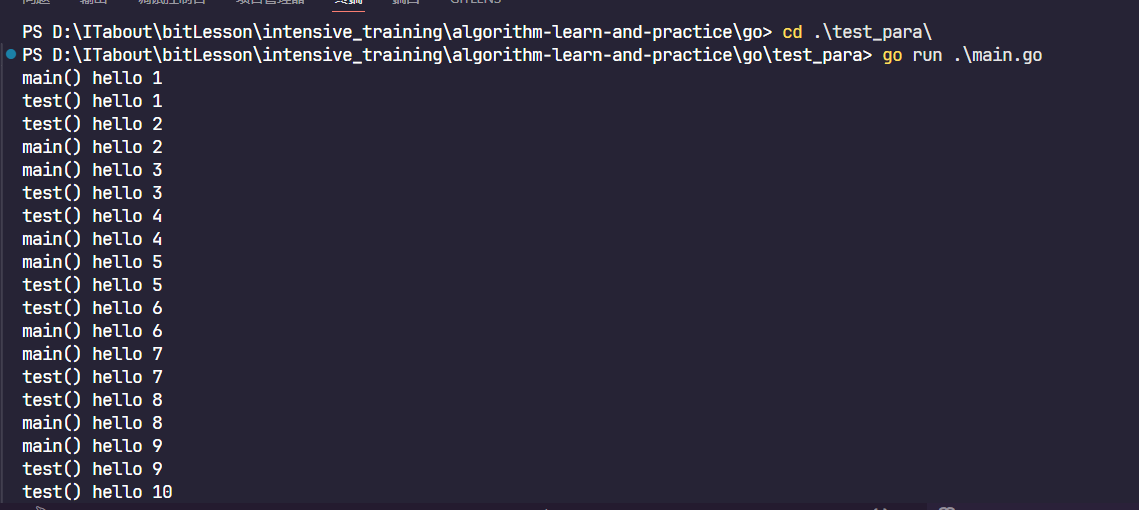
结论:main 结束会导致整个进程退出,所以要么阻塞 main,要么显式等待 goroutine 收敛。
sync.WaitGroup 是最常见的收敛工具。
package main
import (
"fmt"
"strconv"
"sync"
"time"
)
var wg sync.WaitGroup
func test() {
defer wg.Done()
for i := 1; i <= 10; i++ {
fmt.Println("test() 你好 golang "+strconv.Itoa(i))
time.Sleep(50 * time.Millisecond)
}
}
func main() {
wg.Add(1)
go test()
for i := 1; i <= 2; i++ {
fmt.Println("main() 你好 golang "+strconv.Itoa(i))
}
fmt.Println("main loop 执行完成")
wg.Wait()
}

核心范式:
- 启动 goroutine 前
Add(1)。 - goroutine 结束时
Done()(建议defer wg.Done())。 - 主流程最终
Wait()。
5. 启动多个 goroutine(并发执行的随机性)
var wg sync.WaitGroup
func hello(i int) {
defer wg.Done()
fmt.Println("Hello Goroutine!", i)
}
func main() {
for i := 0; i < 5; i++ {
wg.Add(1)
go hello(i)
}
wg.Wait()
}
多次运行会发现输出顺序不固定。
原因很简单:goroutine 的调度顺序不保证。
6. 并行度:设置 GOMAXPROCS(用多少 CPU 核)
Go runtime 会根据 GOMAXPROCS 决定并行执行 Go 代码时可用的 OS 线程数量。
- Go 1.5 之后,默认值通常是 CPU 核心数。
- 你也可以手动调整:
package main
import (
"fmt"
"runtime"
)
func main() {
cpuNum := runtime.NumCPU()
fmt.Println("cpuNum=", cpuNum)
runtime.GOMAXPROCS(cpuNum - 1)
fmt.Println("ok")
}
工程建议:
- 一般不必手动设置,除非你有明确的性能/隔离目标(例如容器限制、与其他进程共享 CPU)。
7. channel:goroutine 之间的通信机制(CSP 思想)
- channel 是 Go 在语言级别提供的 goroutine 通信方式。
- Go 的并发模型强调:通过通信共享内存,而不是通过共享内存实现通信。
channel 的关键特性:
- 有类型:
chan int、chan string等。 - FIFO:先进先出。
- 支持发送、接收、关闭。
var ch chan int
ch = make(chan int, 10) // 默认创建10个 int类型的数据大小缓冲
ch <- 10 // send
x := <-ch // receive
close(ch) // close
- 无缓冲:发送和接收必须同时就绪,否则阻塞。
- 有缓冲:缓冲未满时发送不阻塞,缓冲为空时接收阻塞。
一个经典的死锁示例(无缓冲且无人接收):
ch := make(chan int)
ch <- 10 // 阻塞
for v := range ch {
_ = v
}
关闭 channel 的基本原则:
- 由发送方关闭。
- close 表示“不会再发送”,不是“没有数据”。
8. goroutine + channel:生产者-消费者(同步进行)
示例:一个 goroutine 写入数据,另一个读取数据。
package main
import (
"fmt"
"sync"
"time"
)
var wg sync.WaitGroup
func writeData(ch chan int) {
defer wg.Done()
for i := 0; i < 100; i++ {
ch <- i + 1
time.Sleep(100 * time.Millisecond)
}
close(ch)
}
func readData(ch chan int) {
defer wg.Done()
for v := range ch {
fmt.Println("read", v)
time.Sleep(50 * time.Millisecond)
}
}
func main() {
ch := make(chan int, 100)
wg.Add(2)
go writeData(ch)
go readData(ch)
wg.Wait()
}
这段代码体现了 CSP 的直观好处:
- 写与读解耦。
- 通过 channel 自然形成背压与退出机制(close + range)。
9. 单向 channel:限制函数职责(只写 / 只读)
当你希望一个函数“只负责发送”或“只负责接收”,可以用单向 channel 做约束:
func sender(out chan<- int) {
out <- 1
close(out)
}
func receiver(in <-chan int) {
fmt.Println(<-in)
}
好处:
- 接口更清晰。
- 编译期就能避免误用(比如接收端误发送)。
10. select:多路复用(同时等待多个 channel)
当你要同时从多个 channel 接收,或要加超时/默认分支时,用 select。
select {
case v := <-ch1:
_ = v
case v := <-ch2:
_ = v
default:
// 都没准备好就走这里(非阻塞)
}
典型用途:
- 同时消费多个来源。
select + time.After做超时。select + ctx.Done()做取消。
11. 并发安全与锁:什么时候需要 Mutex / RWMutex
并发程序里,如果多个 goroutine 同时读写同一份共享变量,并且读写之间没有建立“同步关系”(锁、channel、atomic 等),就会出现数据竞争(data race)。
工程上你需要掌握两件事:
- 怎么发现 race(
-race),以及 race 的典型表现。 - 怎么选同步手段:
Mutex/RWMutex/atomic/channel(各有边界与适用场景)。
下面代码看似只是对 counter 做加法,但 counter++ 不是原子操作(读 -> 加 -> 写),多个 goroutine 交错执行会丢失更新。
package main
import (
"fmt"
"sync"
)
func main() {
var counter int
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
counter++
}()
}
wg.Wait()
fmt.Println("counter=", counter) // 理论上应该是 1000,但经常小于 1000
}
用 race detector 跑:
go run -race main.go
你会看到类似 WARNING: DATA RACE 的提示(这在开发阶段非常有价值)。
sync.Mutex 的语义是:同一时刻只能有一个 goroutine 进入临界区。
package main
import (
"fmt"
"sync"
)
func main() {
var (
counter int
mu sync.Mutex
wg sync.WaitGroup
)
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
mu.Lock()
counter++
mu.Unlock()
}()
}
wg.Wait()
fmt.Println("counter=", counter) // 稳定为 1000
}
工程建议:
- 临界区尽量小,不要把慢 IO(网络/磁盘)放在锁里。
- 习惯写成
mu.Lock(); defer mu.Unlock()能减少遗漏解锁的概率,但要注意 defer 的开销与锁持有时间。
sync.RWMutex 允许:
- 多个读(
RLock)并发。 - 写(
Lock)仍然互斥,并且会阻塞新的读。
下面是一个最典型的共享 map 场景:
package main
import (
"fmt"
"sync"
)
// SafeCounter 是一个线程安全的计数器结构体
type SafeCounter struct {
mu sync.RWMutex // 读写锁,用于保护并发访问
m map[string]int // 内部存储,key为字符串,value为计数值
}
// NewSafeCounter 创建并返回一个新的 SafeCounter 实例
func NewSafeCounter() *SafeCounter {
return &SafeCounter{m: make(map[string]int)} // 初始化 map
}
// Inc 对指定 key 的计数值进行加 1 操作(写操作)
func (c *SafeCounter) Inc(key string) {
c.mu.Lock() // 加写锁,确保独占访问
c.m[key]++ // 对 key 对应的值加 1
c.mu.Unlock() // 释放写锁
}
// Get 获取指定 key 的计数值(读操作)
func (c *SafeCounter) Get(key string) int {
c.mu.RLock() // 加读锁,允许多个 goroutine 并发读
v := c.m[key] // 读取 key 对应的值
c.mu.RUnlock() // 释放读锁
return v // 返回读取的值
}
func main() {
c := NewSafeCounter() // 创建线程安全的计数器实例
var wg sync.WaitGroup // 用于等待所有 goroutine 完成
// 启动 1000 个 goroutine 进行写操作
for i := 0; i < 1000; i++ {
wg.Add(1) // 增加 WaitGroup 计数
go func() {
defer wg.Done() // goroutine 结束时减少 WaitGroup 计数
c.Inc("a") // 对 key "a" 的值加 1
}()
}
// 启动 10 个 goroutine 进行读操作(并发读不互斥)
for i := 0; i < 10; i++ {
wg.Add(1) // 增加 WaitGroup 计数
go func() {
defer wg.Done() // goroutine 结束时减少 WaitGroup 计数
_ = c.Get("a") // 读取 key "a" 的值(这里忽略返回值)
}()
}
wg.Wait() // 等待所有 goroutine 完成
fmt.Println("a=", c.Get("a")) // 输出最终结果,应该稳定为 1000
}
注意:
- Go 原生
map在并发写(甚至读写混用)时会直接 panic,所以共享 map 基本都需要:锁 /sync.Map/ 单 goroutine 管理。
如果共享状态只是“一个数”或“一个标志”,用 sync/atomic 往往更轻量。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var counter int64
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
atomic.AddInt64(&counter, 1)
}()
}
wg.Wait()
fmt.Println("counter=", counter)
}
选型建议:
- atomic 适合“很小的共享状态”。
- 一旦你的临界区包含多个字段的组合更新,优先回到锁(atomic 组合操作容易写错)。
另一种思路是:不要让多个 goroutine 直接操作共享变量,而是把状态交给一个 goroutine 独占管理,其他 goroutine 通过 channel 发请求。
package main
import (
"fmt"
"sync"
)
type Inc struct{}
type Get struct {
reply chan int
}
func main() {
reqCh := make(chan any)
// 状态只在这个 goroutine 内部被修改:没有锁也安全
go func() {
counter := 0
for req := range reqCh {
switch r := req.(type) {
case Inc:
counter++
case Get:
r.reply <- counter
}
}
}()
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
reqCh <- Inc{}
}()
}
wg.Wait()
reply := make(chan int, 1)
reqCh <- Get{reply: reply}
fmt.Println("counter=", <-reply)
close(reqCh)
close(reply)
}
这种方式的优点是:逻辑更接近“消息驱动”,容易做队列化、限流、优雅退出。
代价是:结构更复杂,且需要设计请求协议。
- 简单计数/标志位:优先
atomic。 - 共享结构(map、struct 多字段):优先
Mutex。 - 读多写少:考虑
RWMutex。 - 希望避免共享内存,或要天然排队、背压、单线程化状态机:考虑
channel让一个 goroutine 独占状态。 - 开发阶段:强烈建议把
-race当成必跑项(能提前暴露非常隐蔽的 bug)。
12. goroutine 里的 panic:用 recover 保住进程
goroutine 内发生 panic,如果没有在 该 goroutine 内部 做 recover,默认会被 Go runtime 视为“未处理异常”,最终会导致 整个进程崩溃(打印堆栈后退出)。
这一点在服务端程序里很关键:你通常希望“单个任务失败”被隔离,而不是把整个服务带崩。
panic会触发当前 goroutine 的“异常展开”,并执行该 goroutine 栈上已注册的defer。recover只有在<strong>defer</strong>函数里调用才有效,用于捕获正在发生的panic并阻止其继续向外扩散。recover只能处理 当前 goroutine 的 panic:- 主 goroutine 里无法 recover 子 goroutine 的 panic。
- 所以必须在启动 goroutine 的入口处就包好保护层。
import (
"log"
"runtime/debug"
)
func safeGo(fn func()) {
go func() {
defer func() {
if r := recover(); r != nil {
// 1) 记录 panic 值
// 2) 记录堆栈,便于定位
log.Printf("goroutine panic: %vn%s", r, debug.Stack())
// 注意:不要再 panic,否则还是会把进程带崩
}
}()
fn()
}()
}
要点:
recover()返回any,可能是error、string或自定义类型。debug.Stack()能把当时的调用栈打出来,比只打印r好排查很多。
1) recover 不在 defer 里调用:无效
func f() {
if recover() != nil { // 无效
}
}
2) defer 写晚了:来不及兜底
go func() {
fn() // 这里 panic 会直接崩,下面的 defer 没机会注册
defer func() { _ = recover() }()
}()
3) recover 之后什么都不做:任务悄悄死掉
工程上至少要做:
- 记录日志(包含堆栈)。
- 上报指标(panic 次数)。
- 必要时触发告警或让上层感知失败(例如任务队列重试)。
- 适合 recover:请求处理、消息消费、定时任务这类“单次任务 goroutine”,失败应该被隔离。
- 不适合无脑 recover:如果 panic 表示关键不变量被破坏,继续跑可能造成更大破坏。此时更合理的策略是:记录信息后退出,让 supervisor/k8s 重启。
实践建议:边缘 goroutine(任务入口)recover;核心关键路径尽量不要吞 panic。
13. 小结:写 goroutine 的三条工程原则
- 收敛:启动多少 goroutine,就要能等待它们结束(WaitGroup / channel close)。
- 退出:goroutine 必须有退出条件(读到 close、收到 ctx.Done、或内部错误)。
- 边界:并发要有限制(worker pool、队列长度、限流、超时)。
如果你希望我把这篇“协程博客”进一步增强到更工程化(加入 context、worker pool、超时取消、goroutine 泄漏排查与 pprof/trace 指引),我也可以在现有页面上继续扩写。
名词解释
Go runtime
在 Go 语言中,runtime 是指 Go 运行时系统,它负责管理 goroutine 的调度和执行。
具体来说,runtime 的核心职责包括:
- goroutine 调度:runtime 负责在用户态管理和调度所有的 goroutine,决定哪个 goroutine 在哪个 OS 线程上运行
- 内存管理:包括 goroutine 栈的动态增长(初始约 2KB,可按需增长)
- 并行度控制:通过
GOMAXPROCS设置,runtime 决定并行执行 Go 代码时可用的 OS 线程数量
runtime 使得 goroutine 能够以很低的创建和切换开销运行,这也是为什么 Go 可以轻松支持成千上万个并发 goroutine 的原因。
你可以通过 runtime 包与运行时系统交互,例如:
runtime.NumCPU()– 获取 CPU 核心数runtime.GOMAXPROCS()– 设置可用的 CPU 核心数
CSP思想
CSP 思想(Communicating Sequential Processes,通信顺序进程)是一种并发模型:把并发程序拆成很多“顺序执行的独立单元”(process),它们不共享内存,而是通过消息传递(communication)来协作。
在 Go 里,这个思想基本对应一句话:不要通过共享内存来通信,而要通过通信来共享内存。核心实现手段就是 goroutine + channel。

